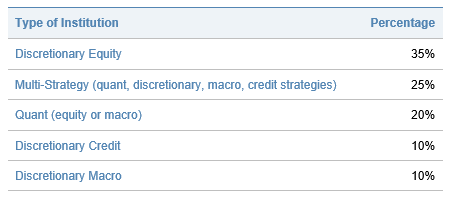
What are some of the challenges of working with alt data, and how do you address these?
There are at least three key challenges in handling alternative datasets.
The first is the size of the data. In the past we were dealing in megabytes but now we are talking about terabytes of data, which needs to be carefully managed within our infrastructure. One way we have tackled this challenge is to make use of a virtual private cloud, which allows us to handle vast quantities of data without having to invest directly in the hardware necessary to consume it. This is changing the way we do things and enables us to be more flexible and agile. Using this approach, we recently onboarded a dataset that is around eight terabytes in size - it would have been impossible to ingest this straight into our existing infrastructure in a short period of time.
The second challenge relates to handling the morphological characteristics of alternative data. Traditional data has an identifiable set of metrics that can be anticipated in the design of data processing systems: for instance, a daily close bar for a futures market will always have Open, High, Low, Close, Volume and Open Interest. Traditional data can therefore be stored in a fixed system design. But alternative data, in contrast, needs to be handled using a flexible system design: the dimensions of the data can be orders of magnitude larger than for traditional data, and those dimensions likely cannot be anticipated in advance as each dataset will have its own idiosyncrasies. For example, flow data will have multiple metrics that are unique even when compared against other flow datasets. Additionally, the dimensions may vary over time. Take for example Nowcasting data, which is commonly generated using an econometric model. The vendor might be forced to re-calibrate its model in certain circumstances, and with re-calibration they might release a new historical dataset, deprecating the previous history. Ignoring the old history and using the new one for back-testing purposes is a recipe for overfitting back-tests. Such time-varying complexity must be handled elegantly to avoid pitfalls, so again flexibility in the system that handles alternative data is crucial.
Finally, the complexity and detail of some of the newer datasets can require a greater degree of collaboration between the Data team and the Research teams. We can no longer just process the data and make it available to the researchers for their use: we need to work closely with them to ensure the data is correctly processed and is made available to them in the most useful way. It’s no longer just a research problem, it’s also an engineering problem.
Then of course there is the issue of assessing the return on investment of new datasets. This is an interesting problem to solve and one which primarily falls to the investment teams to assess before we pull the trigger on a new dataset.
What about the compliance challenges? Do you have a formal data policy in place?
Yes, we have a data procurement policy in place for non-traditional datasets, with the Data, Legal and Compliance teams all having a role to play. We adopt a risk-based approach, considering both the nature of the data itself and the data vendor.
Some of the obvious things we are trying to address through this process are whether the data has been legitimately obtained, whether the vendor has the right to sell it to us and whether it might contain material non-public information; while other, less obvious red flags include whether the data is being offered to us exclusively as this may convey an unfair informational advantage. The UK’s FCA is alive to the possibility that access to alternative data can impact the integrity of financial markets, whilst admitting this is a grey area and acknowledging the need for market participants to innovate[1]. So, it’s important that we self-police in this area and take a thoughtful approach when appraising new, non-traditional datasets.
Our process is based on our years of experience and addresses the compliance and regulatory challenges head-on. This is a cross-departmental process to ensure we have considered all risks and addressed all potential concerns before the data enters the organisation.
[1] https://www.fca.org.uk/insight/turning-data-inside-out
Why is Aspect well-placed to capitalise on the growth of alt data? Does it represent a competitive advantage?
We have a dedicated, centralised Data team with many years’ experience of working on complex data challenges. The team provides a unique technical service in maintaining the data systems that drive our front, middle and back office functions. Within the team, data engineers are concerned with creating and maintaining data applications/data pipelines that process the data before it is used for signal generation, while data analysts are more involved with the analysis of datasets themselves and assessing new business requirements around data. The Data team designs our overall strategy and also works with a cross-departmental group to analyse new datasets and establish whether they may be of use to one or more of our research teams.
We also naturally find that we are approached by a vast number of data vendors who recognise Aspect as a leading name in the systematic investment industry. This acts as a natural competitive advantage and ensures that, if there is an interesting new dataset out there, we should generally know about it.
Finally, as an organisation employing Agile software practices, we are able to act nimbly and to push into new areas of data and technology in a very reactive way.
What proportion of datasets that are reviewed ultimately make it into your models? How many datasets have you reviewed over the past year or so?
That is a difficult question to answer, because for some datasets, the bank of data is vast, so we could have multiple looks at the data and by intelligently slicing and dicing it, we can come up with a multitude of uncorrelated features each time. But I would say that we have looked in detail at around 15 alternative datasets since the beginning of 2019 and we are currently using four of those in production.
In terms of actual results, what impact has the use of alternative data had on the performance of your investments programmes?
2020 has been a great out-of-sample test of the efficacy of these datasets. We have seen traditional, slow-moving macro datasets being quite ineffective in predicting market direction due to the unprecedented economic and macro impact of the pandemic and the associated central bank action. Conversely, alternative data-based models have captured the oscillating market sentiment well and contributed strongly – and importantly, in an uncorrelated fashion – to performance within our Systematic Global Macro Programme.
Do you see the use of alternative data expanding in the coming years?
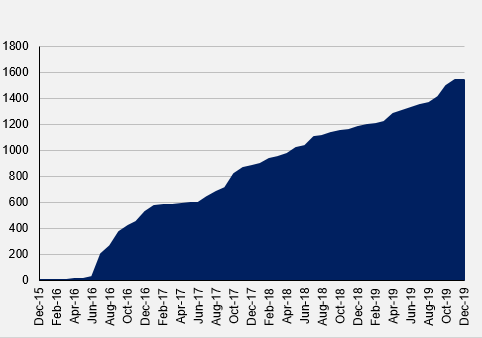
Absolutely. The opportunity is ever-growing as not only the number of available datasets increases (see Figure 1) but so does the length of the histories. If you take a dataset that began in the aftermath of the GFC, for example, a user of that dataset will now be able to see how that data has played out over more or less a full market cycle, encompassing the huge equity bull-run of the last ten years or so, its dramatic dislocation in the wake of the Covid-19 crisis and the aftermath of that shock so far. This ability to test and validate hypotheses through different market cycles and events is vital and will make these newer datasets all the more appealing over time. For these reasons, the use of alternative data is rapidly pervading across the financial industry in one form or another.